Nvidia Bikin Teknologi AI Baru yang Hemat GPU 8x Lipat Tanpa Turunkan Akurasi
– Nvidia mengembangkan teknik baru yang diklaim mampu memangkas kebutuhan memori komputasi kecerdasan buatan (AI) hingga delapan kali lipat tanpa menurunkan akurasi model.
Teknologi tersebut dinamakan dynamic memory sparsification (DMS), yang dirancang untuk mengoptimalkan penggunaan memori pada large language model (LLM) saat melakukan penalaran (reasoning).
Dengan teknik ini, beban pada GPU bisa ditekan signifikan, sehingga sistem AI dapat berjalan lebih efisien.
Atasi bottleneck memori
Dalam model bahasa besar seperti yang digunakan pada chatbot modern, proses penalaran menghasilkan apa yang disebut key-value cache (KV cache), yakni memori sementara yang terus membesar seiring model menghasilkan token demi token saat berpikir.
Baca juga: Waspada Nvidia, Intel Mau Bikin GPU Khusus untuk Server AI
Semakin panjang proses reasoning, semakin besar pula memori yang dibutuhkan GPU. Kondisi ini menjadi salah satu hambatan utama dalam pengembangan sistem AI berskala besar karena meningkatkan biaya komputasi dan membatasi jumlah pengguna yang bisa dilayani secara bersamaan.
Menurut Nvidia, DMS memungkinkan model “mengelola memorinya sendiri” dengan memilih token mana yang perlu dipertahankan dan mana yang dapat dihapus, tanpa mengganggu kualitas output.
Tak turunkan akurasi
Pendekatan ini berbeda dari metode sebelumnya yang menggunakan aturan tetap (heuristik) untuk menghapus memori lama. Teknik lama sering kali mengorbankan akurasi karena membuang informasi penting.
Sebaliknya, DMS melatih model untuk mengenali token yang benar-benar relevan bagi proses penalaran berikutnya.
Baca juga: Nvidia Perbarui GPU AI RTX Pro 5000 Blackwell, VRAM Naik 50 Persen
Nvidia juga menerapkan mekanisme delayed eviction, yaitu menunda penghapusan token agar model masih sempat menyerap konteks penting sebelum memori dibersihkan.
Dalam pengujian pada sejumlah model seperti Qwen dan Llama, DMS menunjukkan peningkatan efisiensi tanpa penurunan performa.
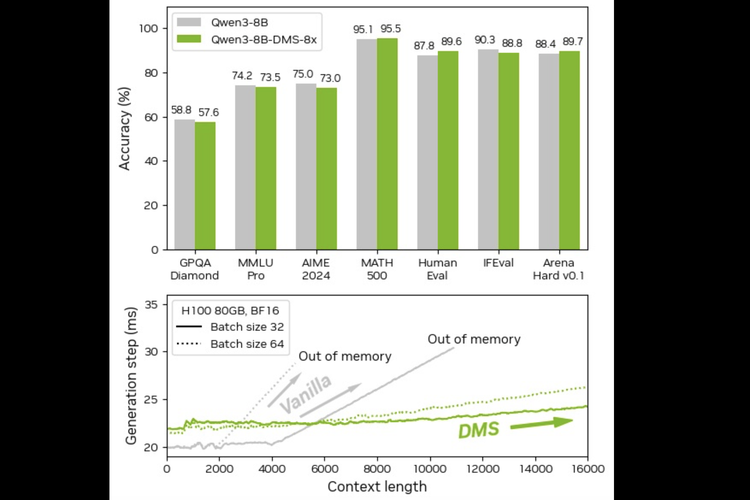 Perbandingan AI Qwen3-8B tanpa DMS dan dengan DMS Nvidia.
Perbandingan AI Qwen3-8B tanpa DMS dan dengan DMS Nvidia.
Dilansir KompasTekno dari VentureBeat, pada beberapa benchmark matematika dan pengkodean (coding), model yang dilengkapi DMS bahkan mencatat skor lebih tinggi dibanding versi standar dengan anggaran komputasi yang sama.
Efisiensi memori ini berdampak langsung pada penggunaan GPU. Dengan cache yang lebih kecil, GPU tidak perlu terus-menerus membaca dan menulis data dalam jumlah besar, sehingga latensi berkurang dan throughput meningkat.
Dalam pengujian pada model Qwen3-8B versi standar (vanilla) dan versi yang sudah dipasangi teknologi Dynamic Memory Sparsification (DMS), terlihat memiliki tingkat akurasi yang nyaris identik di berbagai benchmark penalaran, seperti MATH 500, HumanEval, hingga AIME 2024.
Baca juga: Nvidia Siap Kirim 80.000 Chip AI Canggih H200 ke China
Bahkan pada beberapa pengujian, versi DMS mencatat skor sedikit lebih tinggi. Perbedaan signifikan justru terlihat pada efisiensi memori dan stabilitas performa.
Qwen3-8B biasa mengalami lonjakan penggunaan memori seiring bertambahnya panjang konteks, hingga berujung “out of memory”.
Sebaliknya, versi dengan DMS mampu menjaga waktu generasi tetap stabil dan menghindari kehabisan memori, sehingga model dapat memproses konteks yang lebih panjang tanpa membebani GPU secara berlebihan.
Bagi perusahaan, penghematan ini dinilai signifikan karena biaya infrastruktur AI saat ini sangat bergantung pada kapasitas GPU dan memori.
Bisa dipasang di model yang sudah ada
Nvidia menyatakan DMS dapat diterapkan pada model yang sudah dilatih sebelumnya tanpa perlu pelatihan ulang dari awal. Proses adaptasinya disebut relatif ringan dan kompatibel dengan infrastruktur inference standar.
Teknologi ini telah dirilis sebagai bagian dari framework Model Optimizer Nvidia dan dapat diintegrasikan dalam pipeline AI berbasis Hugging Face, maupun sistem dengan dukungan FlashAttention.
Tag: #nvidia #bikin #teknologi #baru #yang #hemat #lipat #tanpa #turunkan #akurasi
KOMENTAR
BERITA TERKAIT

BERITA LAIN DALAM KATEGORI INI